Exporting query data is quite simple as one-two-three:
One:
define your file format
|
1 2 |
CREATE EXTERNAL FILE FORMAT parquetfile1 WITH ( FORMAT_TYPE = PARQUET, DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec' ); |
Two:
define your file location (note: you should have read/write/list permission the path)
|
1 2 |
CREATE EXTERNAL DATA SOURCE ADLS_DS WITH( LOCATION = 'abfss://synapse@deltapoc0storage0dest.dfs.core.windows.net') |
Three:
Create external table in particular location, using format and path from previous steps:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE EXTERNAL TABLE dbo.n10M WITH ( LOCATION = '/n10M', DATA_SOURCE = ADLS_DS, FILE_FORMAT = parquetfile1 ) AS WITH lv0 AS (SELECT 0 g UNION ALL SELECT 0) ,lv1 AS (SELECT 0 g FROM lv0 a CROSS JOIN lv0 b) -- 4 ,lv2 AS (SELECT 0 g FROM lv1 a CROSS JOIN lv1 b) -- 16 ,lv3 AS (SELECT 0 g FROM lv2 a CROSS JOIN lv2 b) -- 256 ,lv4 AS (SELECT 0 g FROM lv3 a CROSS JOIN lv3 b) -- 65,536 ,lv5 AS (SELECT 0 g FROM lv4 a CROSS JOIN lv4 b) -- 4,294,967,296 ,Tally (n) AS (SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM lv5) SELECT TOP (10000000) n1=n, n2=n, n3=n, n4=n, n5=n, n6=n, n7=n, n8=n, n9=n, n10=n FROM Tally |
Took 43sec to save 10M rows with 10 columns, each having numbers from 1 to 10 000 000 🙂
msg output:
|
1 2 3 4 5 |
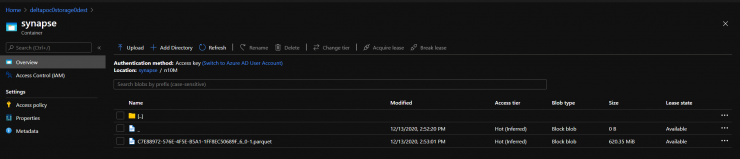
Statement ID: {9510AF69-669C-463C-91B1-F4500CB3F1A3} | Query hash: 0x9478DA6DB082A48 | Distributed request ID: {C7E88972-576E-4F5E-B5A1-1FF8EC50689F}. Total size of data scanned is 0 megabytes, total size of data moved is 0 megabytes, total size of data written is 621 megabytes. (0 rows affected) Completion time: 2020-12-13T14:53:01.5769955+01:00 |
Now, how does it look like in DL?

So far drawbacks are:
- You do not have control over a parquet block size nor filename
- Deleting an external table does not delete a parquet file, which in some scenarios is a good thing 😉
- No partitioning
{kind=link}