
Do tej pory twardo stąpałem po ziemi.
Na łażenie z głową w chmurach i bujanie w obłokach nie było chęci, czasu, możliwości…
Co prawda były jakieś okazyjne wyjazdy i spotkania (i to czasami z własnej kieszeni 😛 – Azure Day w Poznaniu, SQL Day we Wrocławiu, PLSSUG a.k.a. Data Community czy Code Europe w Warszawie), niby wszystko po to, żeby trzymać rękę na pulsie. Ale muszę przyznać, że nawet gdybym codziennie czytał wieści z tamtego świata (i to tylko BI), nie byłbym w stanie wszystkiego ogarnąć. Ilość informacji, jakie pojawiają się w tym obszarze jest przeogromna!
Ale stało się. Będę taplał się w błotku i rzucał mięskiem w samym środku pochmurnego świata jakim jest PaaS i to wśród cukierkowych technologii, których słodko-słony zapach świeżości jeszcze mocno unosi się w powietrzu. Tutaj rządzą inne prawa fizyki! Grawitacja iluzorycznie pozwala podskakiwać z nóżki na nóżkę, cieszyć się od ucha do ucha w tej bajkowej krainie. Ale z wysokich chmurek łatwiej przyjebać porządnie w ziemię i z taką mądrością wkraczam radośnie w nowy świat. On-premises, choć nie tak łatwe i być może jeszcze bardziej kręte i zagadkowe, to jednak przetrzepane na wskroś przez wieloletnie naparzanie developerów T-SQLem i głowami o ściany w milionach projektów na świecie! A tu? Bida z nędzą! Community nie nadąża za zmianami. MS stara się jak może i dokumentacja wraz z samouczkami stoi na dobrym poziomie, ale nie wysokim. Tutoriale, książki, poradniki, pierdolniki… Dlatego postanowiłem podzielić się wrażeniami, doświadczeniami i wkurwami na ile to będzie możliwe. Warto przynajmniej wiedzieć z czym to się je. Bo nawet SQL Server z hurtownią danych nie jest do końca takim SQL Serverem jaki wszyscy znamy, o czym za chwilę…
Ale najpierw ON, wielki ON. Wielki Microsoft Azure. Tajemniczy, nienaturalny i… już na wstępnie sprawiający problemy w kontekście wymowy. Powiedzmy, że powszechnie obowiązuje wersja us, wszak rodowód produktu na to wskazuje. Choć i tak sporo tworzących go tęgich głów pochodzi z kraju na „I”, a ten zaś ma w teorii więcej wspólnego z inną odmianą angielskiego 😉 )
https://dictionary.cambridge.org/pronunciation/english/azure
Pierwsze starcie!

Chcesz wypróbować? Fajnie! Damy Ci w pytę zielonych, kupisz sobie za to kilka rzeczy, ale masz na to 30 dni. Ale, ale! Inne to w ogóle dostaniesz na 12 miesięcy za darmo! A całą resztę to nawet do końca świata!
Daj nam tylko swoją kartę z banku. I obiecujemy nic z niej nie wziąć! No może małą sumkę, żeby tylko sprawdzić kto Ty jesteś, oddamy po kilku dniach. Kiedyś może nam się zdarzyło przypadkiem pobierać opłaty, gdy skończył się trial. Teraz to już możemy się z tego tylko wspólnie pośmiać :> Aaaa, jeszcze telefon! I trochę innych danych…
A czekaj, chciałeś się tylko pouczyć? Nie ma problemu, zajrzyj na dev essentials, damy Ci więcej zielonych. Tylko nie zapomnij wziąć ze sobą karty ! ![]()

Moim zdaniem to wszystko jest zbyt odstraszające, by swobodnie dało się uczyć. Z drugiej strony zdaję sobie sprawę z tego, że inaczej każdy mógłby nadużywać tych rozwiązań. Nie ma jednak niczego pośredniego, jakieś symulacji czy nawet najgłupszych filmików z przeklinania.. Poza tym 30 dni?! Meh..
Wygląda na to, że BI stack, z którym będę miał do czynienia to głównie ADFv2, ADWH, AAS i PowerBI. Zapowiada się ciekawie 😀 W sumie to już jest…
Pamiętacie projekt Micorosft PDW dla SQL Server 2008R2? Nie? Ok, ja też nie 😛
Okazuje się, że przez lata produkt ten ewoluował i ostatecznie trafił też do chmury jako Azure Data Warehouse. PDW to zacna sprawa, no bo jak ogarnąć SQLowe zapytania tak, by mogły być uruchamiane naraz na dziesiątkach serwerów? Wymyślili więc spójną architekturę MPP opartą o zmodyfikowane instancje SQL Server, która ponoć w pochmurnych testach zadziałała najlepiej na 60 nodach dystrybucjach (wszak na jednym nodzie może znaleźć się wiele dystrybucji, jeszcze o tym będę pisał w innym poście). I tak oto zwykli śmiertelnicy mogą stawiać oceany danych (nie takie bezkresne, ale mimo wszystko duże) w architekturze za odpowiednią cenę (za storage i moce przerobowe) i puszczać zapytania równolegle do maksimum 60 maszyn (no tutaj wymagałoby to przedstawienia cennika 🙂 , ale to nie ten moment). Do tego równie ciekawe narzędzia do ładowania (say hello to PolyBase!). Szczegółów i smaczków jest multum! Postaram się je wkrótce opisać. Nosi mnie strasznie, niektóre są przełomowe i aż chce się o nich opowiadać, ale obchodzić się trzeba z nimi ze zdwojoną siłą, cierpliwością i równie wymagającą precyzyjnością… Stay tuned 😉
Na ten moment podzielę się z Wami luźno tym, co mnie zaskoczyło w Azure Data Warehouse:
- Podstawowa instancja DW100 (opt. for elasticity) jeszcze bez żadnych dużych baz startuje ok. 2,5min,
- SSMS zawiera tylko drobny wycinek funkcjonalności, które obsługuje względem zwykłych serwerów. Często SCRIPT AS nie działa, nie ma opcji PROPERTIES. Zostaje query i czysty T-SQL :> (ver. 17.5),
- Visual Studio nie obsługuje do tej pory projektów bazy dla ADWH! Jest zgłoszony taki ficzer pod głosowanie i oczywiście jest w kolejce jako pierwszy…od kwietnia 2016r. Srsly? W połączeniu z SSMSem
gubiącym definicje collation(jednak da się włączyć w opcjach scriptingu) czy np. kluczy dystrybucji, development kończy się robótkami ręcznymi w plikach i ich ręcznym deploy (więc pewnie skończy się to jeszcze na budowaniu skryptów ps…). Czy wspomniałem już, że przez SMO i Tasks->Generate Scripts też nie pójdzie? Szoking!
(więc pewnie skończy się to jeszcze na budowaniu skryptów ps…). Czy wspomniałem już, że przez SMO i Tasks->Generate Scripts też nie pójdzie? Szoking! - nie ma obsługi cross-database join, wszystko musi dziać się w obszarze jednej bazy i ew. różnych schematów,
- automatyczne tworzenie statystyk jest wyłączone i nie ma możliwości ich włączenia, należy samemu zadbać o wszystkie aspekty z tym związane czyli m.in. samemu je tworzyć z pomocą CREATE STATISTICS ,
- nie ma obsługi rekursywnego CTE w T-SQL,
- funkcje (UDF) mogą być tylko skalarne, na ten moment nie da się utworzyć własnych table-valued czy aggregated,
- procedury mają okrojony T-SQL, nie ma RETURN, maksymalnie 8 nest levels (i nie ma obsługi zmiennej @@NESTLEVEL), nie można przypisać defaultów do zmiennych, INSERT..EXECUTE też nie istnieje (choć można obejść przez tempówki, które są dzielone w sesji i widać je przed procedurą, w trakcie i po 🙂 ) i jeszcze parę innych restrykcji,
- zapytania można LABELować, co później może ułatwić ich ponowne użycie czy identyfikację podczas analizy,
- już samo tworzenie tabel jest małym wyzwaniem, CREATE TABLE dla ADWH ma swoją dedykowaną stronę :>,
- i oczywiście nie ma obsługi kluczy głównych, kluczy obcych, unikalnych czy innych check constraints (czyli indeks nieklastrowy unikalny też NIE istnieje). Ogólnie to wielu rzeczy nie ma 😀 Co akurat rozumiem, natura „rozpraszania” nie pozwala na łatwą implementację… Ale mimo wszystko smuteczek ;(
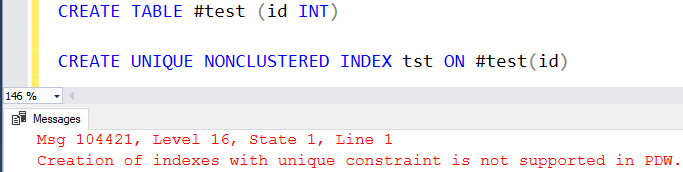
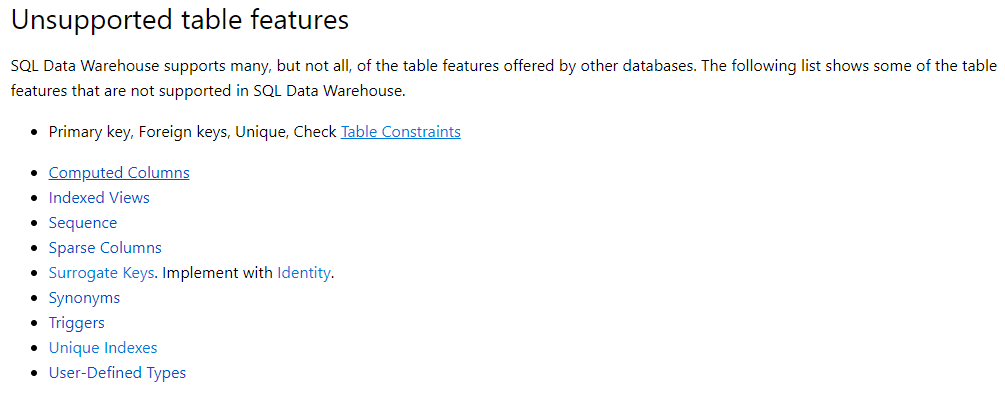
W praktyce opłaca się bardziej wejść na dokumentację i sprawdzić, czy dane polecenie, które chcemy wykorzystać, ma takie applajsy:
![]()
a nie np:
![]()
Reszta ciekawostek pojawi się zapewne w osobnym wpisie. Interesujących różnić jest znacznie, znacznie więcej…
{kind=link}