
Z dokumentacji technet ( http://msdn.microsoft.com/en-us/library/ms175064(v=sql.105).aspx ; http://msdn.microsoft.com/en-us/library/ms178543(v=sql.105).aspx )
„Compares a scalar value with a single-column set of values.”
Wielu z Was zapewne zna i korzystało z polecenia „IN”, które pozwala w prosty sposób sprawdzić w warunku zapytania, czy wskazana przez nas wartość bieżącego rekordu występuje w innym zbiorze. Oczywiście w ten sposób można jedynie porównywać wartości, nie sprawdzimy czy wartości są mniejsze/większe od tych w drugiem secie danych. Podobnie nie da się tego zrobić używając tylko operatorów przy kolumnach. W obu przypadkach próba uruchomienia takiego zapytania zakończy się błędem zwrócenia więcej niż jednej wartości. Np:
SELECT TOP (1000) * FROM [AdventureWorks2012].[Production].[Product] WHERE SellStartDate > (SELECT TOP (100) * FROM [AdventureWorks2012].[Production].[Product])
Wynik:

Problemem jest oczywiście brak deklaracji metody, jakiej mielibyśmy użyć do wykonania takiej operacji logicznej. SQL nie wie, czy dla bieżącej wartości ma wykonać porównanie względem wszystkich wartości w drugim zbiorze czy może wystarczy jak warunek spełnia pierwszy napotkany rekord z drugiego setu.
Z pomocą nadchodzą polecenia SOME, ANY i ALL, które właśnie ten warunek determinują. Poniżej garść kluczowych informacji i próba wyjaśnienia jak one działają 😀
– SOME i ANY są tożsame. Jest to wynik zmian standardu ANSI i prób zaspokojenia deklaratywności języka (jezyk SQL jest ustandaryzowany tj powinien wyglądać i działać tak samo we wszystkich bazach relacyjnych na świecie – co oczywiście nie ma miejsca w 100% ale dzięki temu SQL w SQL Server, SQL w Oracle czy w DB2 są do siebie podobne. Deklaratywność zaś, najogólniej mówiąc, to cecha języka, która określa co chcemy dostac ale nie określa jak to należy zrobić. szczegóły tutaj: http://pl.wikipedia.org/wiki/Programowanie_deklaratywne )
– oba powyższe gwarantują, że zapytanie zwróci rekord, jeśli sprawdzana przez nas wartość spełnia zdefiniowany warunek dla którejkolwiek wartości z drugiego zbioru
– ALL zwróci rekord jedynie wtedy, jeśli sprawdzana przez nas wartość spełnia zdefiniowany warunek dla wszystkich wartości z drugiego zbioru
Przykład:
Mamy dwa zbiory.
Zbiór A zawiera elementy: 100, 200, 1000
Zbiór B: 150, 1000
Chcemy zwrócić takie elementy ze zbioru A, których wartość jest równa lub większa od dowolnego elementu ze zbioru B.
W tym celu wykonamy zapytanie, które dla kolumny element z tabeli #ZbiorA znajdzie większy lub równy co najmniej jeden (SOME albo ANY) element w tabeli #ZbiorB. Jeśli go znajdzie to zwroci wiersz w wyniku.
Jak wyglądałby zatem nasz SQL?
SELECT * FROM #ZbiorA WHERE element >= SOME ( SELECT element FROM #ZbiorB )
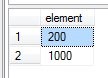
Teraz chcemy zwrócić takie elementy ze zbioru A, których wartość jest większa lub równa względem WSZYSTKICH elementów w zbiorze B.
W tym celu wykonamy zapytanie, które dla kolumny element z tabeli #ZbiorA sprawdzi wszystkie (ALL) elementy w tabeli #ZbiorB. Wynik zostanie zwrócony tylko dla takich elementów #ZbiorA, które sa większe lub równe od wszystkich w #ZbiórB
SELECT * FROM #ZbiorA WHERE element >= ALL ( SELECT element FROM #ZbiorB )
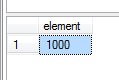
Pełne zapytanie z utworzeniem struktur dostępne poniżej:
CREATE TABLE #ZbiorA ( element INT )
CREATE TABLE #ZbiorB ( element INT )
INSERT INTO #ZbiorA
( element )
VALUES ( 100 ),
( 200 ),
( 1000 )
INSERT INTO #ZbiorB
( element )
VALUES ( 150 ),
( 1000 )
SELECT *
FROM #ZbiorA
WHERE element >= SOME ( SELECT element
FROM #ZbiorB )
SELECT *
FROM #ZbiorA
WHERE element >= ALL ( SELECT element
FROM #ZbiorB )
DROP TABLE #ZbiorA
DROP TABLE #ZbiorB
Dla ambitnych 🙂
Skoro już wiemy, że operacje SOME/ANY i ALL da się wykonywać względem wszystkich operatorów porównania: = , < > , ! = , > , > = , ! > , < , < = , ! <
1. Jak myślisz, jakim powyższym poleceniem możemy zastąpić operację „IN” ?
Odpowiedź (zaznacz tekst aby podejrzeć odpowiedź…)
= ANY ()
2. W takim razie które polecenie zastąpi nam „NOT IN” ?
Odpowiedź (zaznacz…)
<> ALL ()
lub
!= ALL ()
🙂
{kind=link}