
Z dokumentacji technet:
https://msdn.microsoft.com/pl-pl/library/ms189461%28v=sql.110%29.aspx
| ROWS | RANGE Further limits the rows within the partition by specifying start and end points within the partition. This is done by specifying a range of rows with respect to the current row either by logical association or physical association. Physical association is achieved by using the ROWS clause. |
Tajemniczo brzmiący tytuł, ale sprawa warta uwagi i zapamiętania, że w SQLu możliwa jest agregacja wartości na jeszcze głębszych poziomach niż na całości rekordów czy tylko partycji.
Od SQL Server 2012 możliwe jest poruszanie się po „oknie” danych i wykonywanie kalkulacji w dość prosty sposób – posługując się odpowiednimi poleceniami.
Spójrzcie na poniższą tabelkę i przykład zapytania:
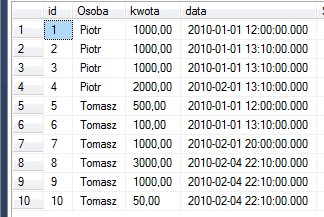
Wykonanie:
SELECT SUM(kwota) OVER(PARTITION BY Osoba ORDER BY data ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
zadziała w następujący sposób:
SUM(kwota) |-> sql dostaje informacje, że będziemy wykonywali operację agregacji danych po polu kwota używając funkcji, która je zsumuje
OVER( |-> daje znac, że nasza operacja nie będzie wykonywana przy użyciu grupowania danych GROUP BY, tylko poprzez ich „partycjonowanie”
PARTITION BY Osoba |-> SQL teraz ma obowiązek grupować okno danych względem pola Osoba, partycja to nic innego ja znalezienie unikalnych wartości w zadanym polu i wykonanie względem nich kolejnych obliczeń (podobnie jak group by, ale tu wykonywane jest to względem każdego rekordu). Jak widać dla nas będą to wartości „Piotr” i „Tomasz”
ORDER BY data |-> poza partycją istotne jest również w jakiej kolejności dostarczymy dane do funkcji agregującej, czyli naszej sumy. Tu zrobimy to rosnąco po polu z datą.
ROWS |-> od tego momentu SQL Server wie, że poziom agregacji danych został obniżony. Innymi słowy zamiast zliczac wartości tylko dla rekordów będących w danej partycji zliczanie będzie się odbywało tylko na wybranych wierszach będących w tej partycji.
To tak jak byście spojrzeli na rekordy od id = 5 do 10. Należą one do partycji „Tomasz”, sumę moglibyśmy wykonac dla całego zbioru i dołączyc ją do każdego rekordu jako osobną kolumnę. Wszędzie miałaby taką samą wartość.
Jednak teraz możemy zmusic SQLa do wybrania tylko części, np od początku partycji aż do bieżącego wiersza, na którym wyliczana jest suma.
Zamiast ROWS moglibyśmy użyć polecenia RANGE które dla powtarzających się wartości w polu z datą wykona sumę od razu, zamiast z osobna dla każdego wiersza jednak dotyczy to tylko tych agregatów, które są od początku do bieżącego wiersza lub od bieżącego aż do końca partycji. Łatwiej zrozumieć będzie to na przykładzie podanym na końcu 🙂
BETWEEN |-> rozpoczynamy deklarację okna w jakim będzie poruszał się agregat. Za chwilę podamy między jakimi rekordami ma się on wykonac.
UNBOUNDED PRECEDING AND CURRENT ROW |-> polecenie to przekazało SQLowi instrukcję: „od pierwszego wiersza partycji do bieżącego, na którym wyliczasz agregat”. Innymi słowy, jeśli liczymy sumę dla partycji „Tomasz” to wylicz ją od pierwszego wiersza aż do miejsca, w którym jesteś. Jeśli jesteśmy np w wierszu 7 to policz sumę od wiersza 5 az do 7 czyli 500+100+1000.
Jak widzicie powyższy przykład nie jest niczym innym jak sposobem na policzenie sumy kroczącej (running sum) na polu kwota dla Piotra i Tomasza licząc ją względem daty 🙂

Dostępne są również następujące okna:
CURRENT ROW AND UNBOUNDED FOLLOWING |-> czyli od bieżącego wiersza aż do końca partycji
UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING |-> czyli od początku partycji aż do jej końca
x PRECEDING AND x FOLLOWING |-> gdzie x to liczba całkowita wyznaczająca ilość wierszy przed i ilość wierszy po, dla x = 1 oznacza to jeden wiersz przed, bieżący i jeden po 🙂 jeśli liczba wykracza poza okno to oczywiście brane pod uwagę są tylko dostępne wiersze, nie zwracany jest żaden błąd
No to teraz pełen kod i przykłady różnych okien danych dla tej samej funkcji agregującej SUM
CREATE TABLE #T(id INT IDENTITY
PRIMARY KEY,
Osoba VARCHAR(50),
kwota MONEY,
data DATETIME);
INSERT INTO #T
VALUES('Piotr', 1000, '2010-01-01 12:00'),
('Piotr', 1000, '2010-01-01 13:10'),
('Piotr', 1000, '2010-01-01 13:10'),
('Piotr', 2000, '2010-02-01 13:10'),
('Tomasz', 500, '2010-01-01 12:00'),
('Tomasz', 100, '2010-01-01 13:10'),
('Tomasz', 1000, '2010-02-01 20:00'),
('Tomasz', 3000, '2010-02-04 22:10'),
('Tomasz', 1000, '2010-02-04 22:10'),
('Tomasz', 50, '2010-02-04 22:10');
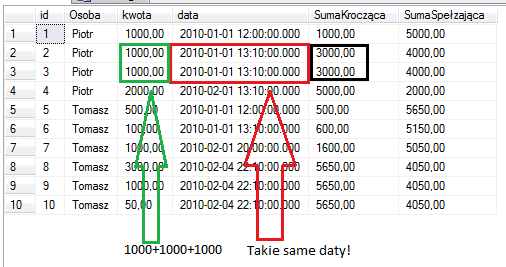
SELECT *,
SumaKroczaca=SUM(kwota) OVER(PARTITION BY Osoba ORDER BY data ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW),
SumaSpelzajaca=SUM(kwota) OVER(PARTITION BY Osoba ORDER BY data ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING),
SumaZPoprzednimINastepnym=SUM(kwota) OVER(PARTITION BY Osoba ORDER BY data ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING),
SumaDlaOsoby=SUM(kwota) OVER(PARTITION BY Osoba ORDER BY data ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
FROM #T
ORDER BY Osoba,
data;
DROP TABLE #T;
Wynik:

To samo, ale z użyciem polecenia RANGE zamiast ROWS :
CREATE TABLE #T(id INT IDENTITY
PRIMARY KEY,
Osoba VARCHAR(50),
kwota MONEY,
data DATETIME);
INSERT INTO #T
VALUES('Piotr', 1000, '2010-01-01 12:00'),
('Piotr', 1000, '2010-01-01 13:10'),
('Piotr', 1000, '2010-01-01 13:10'),
('Piotr', 2000, '2010-02-01 13:10'),
('Tomasz', 500, '2010-01-01 12:00'),
('Tomasz', 100, '2010-01-01 13:10'),
('Tomasz', 1000, '2010-02-01 20:00'),
('Tomasz', 3000, '2010-02-04 22:10'),
('Tomasz', 1000, '2010-02-04 22:10'),
('Tomasz', 50, '2010-02-04 22:10');
SELECT *,
SumaKroczaca=SUM(kwota) OVER(PARTITION BY Osoba ORDER BY data RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW),
SumaSpelzajaca=SUM(kwota) OVER(PARTITION BY Osoba ORDER BY data RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
FROM #T
ORDER BY Osoba,
data;
DROP TABLE #T;
Wynik:
{kind=link}
Super wytłumaczone. Oby więcej takich wpisów. Pozdrawiam i dziękuje !
I ja dziękuję za komentarz 🙂
Fajnie, że te treści wciąż się przydają i są aktualne, choć mają już swoje lata 🙂 SQL na szczęście się nie starzeje, co innego chmura – niektóre posty (piszę je po angielsku) już nie mają kompletnie zastosowania po dwóch latach…
Zapraszam więc do innych materiałów, z pewnością coś ciekawego jeszcze tu znajdziesz dla siebie 🙂
http://sql.pawlikowski.pro/wszystkie-posty/
Powodzenia i pozdrawiam!
Dzięki, właśnie rozwiązałeś mój problem nad którym siedzę od 2 godzin 🙂
Dzień dobry, czy jest możliwość sumowania wierszy od pierwszego do przedostatniego lub podanie przedostatniego wiersza?